
(Summary in Finnish: Oppimispäiväkirjamerkinnät jatkuvat, hitaasti mutta kumminkin. Aiheena luvut 3 ja 4; luvusta 3 löysin paljon sanottavaa kun aloin kirjoittamaan.)
Context: This is a part in a series of reading / study diary notes where I track my thoughts, comments, and (hopefully) learning process while I am reading How to Measure Anything by D. W. Hubbard together with some friends in a book club like setting. Links to previous blog entries: vol. 0 (introduction); vol. 1. All installments in the series can be identified by tag “Measure Anything” series on this blog.
This part of the series is quite behind the schedule of the book club (we have already discussed Chapter 7 and will talk about 8 & 9 this week). The reason for the lateness of the current installment is that I felt inspired to say quite much about Chapter 3 when I reviewed my notes some time after the book club meet.
Summary of lessons from Chapters 3 & 4
In Chapter 3, Hubbard presents more detailed discussion of concept of “what is measurement”. . In the following chapter, we start our journey into studying the concepts how to measure something (hopefully, anything) following author’s advice by talking what is a practical measurement problem.
On Chapter 4, which discusses framing a good measurement problem, I have much less to say.
Onto it!
Measurement as approximation
Hubbard starts Chapter 3 with a quote from Bertrand Russell:
Although this may seem a paradox, all exact science is based on the idea of approximation. If a man tells you he knows a thing exactly, then you can be safe in inferring that you are speaking to an inexact man.
—Bertrand Russell (1873–1970)
…while Hubbard has much more to say, the quote summaries the point I’d consider my most important take-away from Chapter 3. The exact measurements are rare-to-impossible; modern science and engineering is concerned with approximations or (even better) quantified tolerances.
The reason I consider this personally the most important lesson to me is that I was both surprised yet I should have know this: for my master’s thesis, I studied a set of tomographic reconstruction algorithms for X-ray computed tomography of pipe section welds for industrial applications. While the particular application and set of algorithms I experimented with were relatively novel, the relevant technology in general is example of established field of science and engineer: in medical applications, CT scans are something people trust. Yet every such device has to deal various sources of noise and measurement imprecision. At the very best, I can quantify the amount of error in ones measurements in a way I can trust. This does not preclude improving the method so that the amount of error gets small enough for the desired purpose. However, to convince myself and others that the amount of error is bounded, I need some kind of proof of it.
Likewise, one of the important part to consider when applying any practical, numerical algorithm to solve any mathematical problem is the formal quantification of amount of error in the numerical solution.
A digression to demonstrate this. Consider a classic dynamic system (Wikipedia) that models a closed ecosystem with one predator and one prey species population, where the predator (say, lynx) feeds on the prey (say, rabbits). Let us assume the rate of change of size of predator population at any given moment depends on availability of the prey and similarly for the prey population. This results in boom bust cycles for both (plot). Given the mathematical equations for this kind of dynamical system, the most classic and easiest method to “draw” this kind of a plot for a described dynamic system is to calculate the evolution of the system at each individual time point, step by step with step length 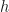
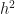
So, considering all of the intuition into measurement and error above, I am quite appreciative to Hubbard’s central claim of the chapter 3: obtaining approximations that are good enough is the useful standard of measurement is a good standard definition for measurement. Thus it the other central claim is also plausible, namely, reducing ones uncertainty is also a measurement in more fuzzy domains – or domains incorrectly viewed as fuzzy and intangible.
Rest of Chapter 3
Other points worth noting from Chapter 3 include some discussion into how to define the thing being measured, about methods for measuring things and some common objections, such as when it worth the cost of measurement to measure things.
First, the object of measurement. Hubbard argues (quite convincingly) that if anything is considered important, the qualities that make it important have noticeable effects on the wider world. Consequently, if these effects are noticeable, they also can measured rigorously. This is demonstrated by several more or less persuasive examples from author’s career in consulting (which I see no point in repeating here, read the book yourself).
My only reservation is that while the chain of reasoning is quite valid in abstract, for some qualities the useful practical measurement may be prohibitively difficult (expensive), but maybe this will be discussed in more detail in a later chapter concerning value of information.
Secondly, methods of measurement. Concerning the methods, the book actually makes two distinct points. The first one is that there are many established statistical procedures for measuring various quantities about unknown quantities of any population. The second point is a couple of simple rules that illustrate how small amounts of good information tell a lot more than nothing. Consequently, when one does not know anything, almost any effort at knowing more is very useful. This is surprising, and I am half convinced
This is demonstrated by two statistical “rule of thumb” theorems that are quite surprising (or maybe not) and I think are worthwhile paraphrasing here in more detail:
The Rule of Five. There is a 93.75% chance that the median of a population is between the smallest and largest values in any random sample of five from that population.
Remember, the median of the population is the point that separates that mass of the population distribution in half. If you feel inclined, working out the proof the statement is quite trivial from that fact, and assuming one takes five independent samples. At first the statement sounds quite surprising, almost magical: five samples from a population is not a lot. However, if one has a very wide or otherwise not nice underlying distribution, the minimum and maximum of the sample of five is quite likely to cover a wide range.
The Single Sample Majority Rule (or, The Urn of Mystery Rule). (Rephrased.) Assume a population with a binary quality. such as, an urn that contains balls that can be of two different colors. If the proportion
between different colors is unknown and one considers all proportions between equally likely a priori. Under these assumptions, there is a 75% chance that a single random sample is from the majority of the population.
Again, the proof is not difficult. (Hint: Start by noting equal probability for all 

However, I said I am halfly convinced. The argument is two-pronged: Yes, both the Rule of Five and the Urn of Mystery Rule sound surprising. Approximate 94% chance that the median of a population is withing five independent samples from it sounds large, and is useful to know, but as I said, with large distributions that range can be surprisingly large. Likewise, in the Urn Rule, 75% is a lot, but so is 25%, and it is based on assuming an uniform uncertainty about the true proportion. Uniform distribution is a reasonable choice in that it is a maximum entropy distribution between 0 and 1, or in layman’s terms, it conveys maximum uncertainty about a quantity given the upper and lower bounds for quantity’s range. However, sometimes one knows more than nothing, which has noticeable effects.
On the other hand, if one does not really nothing, the Urn of Mystery Rule still applies only to observation about a single binary quality. Why this is important caveat?
Example. Consider the population of students at one particular university, and let us assume you meet one of them (single random sample). Choose one quality of student, for example, whether their GPA is high or low (defined as GPA 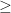
However, if you don’t have any reason to believe that these qualities are correlated, and the student you meet is tall LISP programmer who wears clothes with lots of color blue and has high GPA and highly educated parents, the probability that the majority of the student population is likewise in all these qualities is $0.75 \cdot 0.75 \cdot 0.75 \cdot 0.75 \cdot 0.75 \approx 0.237$, which is (i) much smaller number than 0.75 and becomes more smaller more qualities about the person feel salient to you and also (ii) unrealistic, in the sense than one probably has better than total uncertainty about things like popularity of LISP. Moreover, if you consider qualities that are not easily thought about as a binary (e.g. hair color), the calculation becomes different. [/end of example]
Nevertheless, I can not find myself disagreeing with the counterpoint of counterpoint: If you know nothing of the population before taking the five samples, even a very wide range for the median is more than nothing. Same for drawing the first sample from totally unknown population. But one should be aware of hos strong the words of “nothing” and “unknown” are.
edit.And additionally, these considerations illustrate that realizing any small amount of information one has about the subject topic may greatly influence these kind of simple calculations!
When it is worth the costs to measure things?
The question of when it is worth the effort and the inflicted costs to measure something sounds like the final important part of Chapter 3, but in it is not answered in depth. Hubbard’s thesis is that measurement is valuable when there is high cost of being wrong tied to large amounts of uncertainty. There are several examples of common objections (“economic arguments against measurement”) and counterarguments, but I think the basic gist is this: If one wants to argue that measuring something is too difficult or too expensive, one should consider also the difficulties and costs entailed in the case the uncertain risk is realized in an unfavorably way.
(If there is a knowledge that there is no risk or it is acceptable, one already has enough “measurement”. Sounds a bit circular, but circular rephrasing makes the concept easier to appreciate..)
Sounds good in principle, but how to do such comparison in real life? The disappointing answer is, the topic is not much discussed here, but as I have the benefit of progressing some chapters forward in the book, the answer is that a more detailed answer to the question will be explored in later chapters.
Goodhart’s law
I was also quite eager to see when and what the author in favor of “Measuring Anything” would address the Goodhart’s law, which (if you are not familiar with it already) is commonly stated in following words:
When a measure becomes a target, it ceases to be a good measure.
Dame Marilyn Strathern, apparently
For some reason, it is dealt with as one of the “economic arguments” in this chapter. The author acknowledges the dangers, but argues that making measurements and creating incentive structures (that involve measurements) are two different things.
…which, as far as counterarguments go, does not impress me too much. I would argue that the important thing to understand of the Goodhart’s law is this: Making measurements that influence decisions that affect people is a reason for the affected people to adapt their behavior. Sometimes or often some kind of change is wanted, but people can surprise. If the method of measurement is public knowledge, then it becomes (of course) one of the easiest things to adapt to.
The reason why situation is problematic for audience of this book may become more obvious if it is written as an adversarial measurement scenario. Let us imagine party A, having read “How to Measure Anything”, who wants to makes measurements M of some features of intangible target T to make decision which involves interests of another party B. If also the party B has read the book “How to Measure Anything”, they would probably like to measure how to best affect the decisions of part A! If party B can affect both T and M, then they would naturally want to evaluate which one they should work on. (Usually the problem is that M, being specified, is more legible and thus easier to influence than the intangible target that A is really interested about).
I am not super familiar with the relevant game theory and economics, but it seems there would be quite much interesting things to discuss about strategies that arise in this kind of scenarios. Unfortunately, it seems it is an interesting topic for some other book.
Consequently, why continue reading the book? My personal take is that it is fine to follow the way of this book and make measurements without such strategic considerations either if (a) the scenario is not adversarial or (b) if there is an adversarial party involved, they are not measuring your measurements. (Someone might say something about countermeasures.) It feels intuitive to argue that either the measurement is one-off and secret.
Lessons from Chapter 4
Chapter 4 deals with the question how to measure with lots of practical advice and examples, which sound very sensible.
The basic point is quite simple: The problems that appear difficult to made quantifiable can become much easier if one carefully reiterates why the problem is important. Usually this is because there are decisions involved. The first step in Hubbard’s five-step workflow to do this iteration is “defining the decision”: Define what are the stakes and what are the alternatives, which leads to neatly to step 2, determining what you already know about both.
It sounds very simple, but also quite useful. As I said, the book fleshes this out in more detail (so if you are not convinced, maybe read the examples in the book by yourself), but the above is the best summary I think I can make. Techniques such as Fermi decomposition can help, but I feel lots of advice is also quite context dependent.
Measuring relative vs absolute quantities
One point that is mentioned in passing but worth I thought highlighting: when one frames the measurement problem as problem of choosing between two alternatives, both associated with one numeric quantity each, it is not necessary to established absolute magnitude for either. It often suffices to establish the relation between them. Magnitudes matter only to the extent that one must make sure the two quantities are comparable.
Thinking about it, it makes sense: with compositional data, one can say quite many things about relative importance of two quantities by fixing only their relative size. In some applications, fixing the magnitude of the quantities requires.
(Remember my example about dynamical system of rabbits and lynxes? One does not need to count all the rabbits and lynxes in the ecosystem, usually one tries to estimate them with some kind of observational sampling.)
Other points (from the book club discussion)
My discussion notes are not as extensive, and I am writing this nearly two weeks after the discussion. As far the notes go, we apparently mostly talked the main contents of the chapters at hand, reviewed above.
In addition to above,
- we got a reading recommendation: Moral Mazes by Robert Jackall (Wikipedia, GoodReads). (Correction:2021-02-24 The recommendation was for a blog that discusses Jackall’s book.)
- While I did not think it very interesting, book discusses terminology related to Knightian uncertainty. (Hubbard defines “uncertainty” as a lack of certainty and something you can put a number on, and “risk” as uncertainty involving a loss. Knightian meanings for “uncertainty” and “risk” are different.) We talked about about the wider concept of not-quantifiable uncertainty as form of “unknown unknown” as compared to known unknowns.
- See also https://en.wikipedia.org/wiki/Ellsberg_paradox.
- Example of “unknown unknown”: Members of the book club anticipated many various distractions and failure modes for a reading circle. For example, it was not a total surprise that one member was too busy to attend. However, all present were very surprised when we realized that some of us had been using different editions of the book with much difference in the content!
- Related to above, some people have found some use from Cynefin framework.
- In general, there was some amount of agreement that thus far the book as been more conceptual than technical, and we have been familiar with some of the ideas before. (E.g. via Effective Altruism.)
- However, there was some amount of agreement that it is useful to have many of this things collected in a single guidebook or manual that can act as a “checklist”. Checklists are good for aviation, surgery and sometimes pointing and telling the important things aloud!
Conclusion
The chapter 3 started with a blast, by pointing out how measurements can be useful despite them always involving some kind approximation and error. In my comments, I tried to highlight how quantifying the amount of approximation alone can be important! Chapter 3 also talked about various methods of measurement, where I found the two statistical rules (the Rule of Five and the Urn of Mystery) especially salient and worth elaborating. Other important topics included Goodhart’s law (Ch 3) and importance of stating the good measurement problems by identifying the decisions they are about (Ch 4).
I have no further conclusion to write! In our book club, we have already also talked about chapters 5,6,7, which I will write about in the next installment in the blog series. (Hopefully the next post will be public quite soon-ish.)

.svg){kind=link}