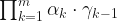Comment: The most interesting thing in the paper was its title. I didn’t know tree-based models are supposed to outperform but I guess they do. I don’t know much about this field, but it sort-of makes intuitive sense: Transformers and prior to them MLP(CNN) architectures have been very impressive at problems in computer vision and natural language — which used to be difficult, because previously the best computer algorithms were not that good at same stuff as our mammalian human brain does 24/7. But “vision” and “natural language” is different kind of difficult than fitting ML models on arbitrary tabular data.
And apparently XGBoost is still good for something. (Learning it wasn’t in vain and it is still relevant?)
However, regressions are run on matrices. Which is to say that when you run a regression in R — and most other languages for that matter — behind the scenes your input data frame is first converted to an equivalent matrix before any computation gets done. Matrices have several features that make them “faster” to compute on than data frames. For example, every element must be of the same type (say, numeric). But let’s just agree that converting a data frame to a matrix requires at least some computational effort. Consider then what happens when we feed our lm.fit() function a pre-created design matrix, instead asking it to convert a bunch of data frame columns on the fly.
McDermott
Torous, William, Florian Gunsilius, and Philippe Rigollet. “An Optimal Transport Approach to Causal Inference.” arXiv, August 12, 2021. https://doi.org/10.48550/arXiv.2108.05858.
Comment: I do not understand optimal transport, but it seems quite cool. (This tutorial paper by Peyré and Cuturi has been resting on my “to-read” shelf since 2020.) Now, earlier this year I have learned a lot of causal inference techniques common in econometrics, such as differences-in-differences. Apparently DiD can be generalized as “CiC” (Changes-in-Changes), but according to Torous and friends, it works poorly and their optimal transport approach works better. (I can’t really say, but graphs look nice.)
For the past year, the blog has been on an unscheduled hiatus because I felt I have very little to say. But this afternoon I stumbled upon a good article by Sander Greenland from 2018 [1] which “rehabilitates” P-values somewhat in my eyes.
Yes, I have used them in my work, but always felt a bit icky about it. Part of it is that during my undergraduate I found the Bayesian version of probability theory easier to reason about, and the Bayesians often scoff at frequentists. But the reasons to do so are real: Misinterpretations of p are common and easy (often I suspect I can’t keep the definitions exactly straight in my head); p is not the probability the alternative hypothesis is true; do I even know the null makes sense; the magical 0.05 boundary feels often both too small and too large and always unjustified; …. often, I have felt like writing verbal equivalents of bright yellow warning signs “I report a P-value because I think everyone wants it or everyone relevant already told me they want it; but you should be careful with it!!”
DANGER, WILL ROBINSON! P-VALUES! DANGER!
Greenland’s article was helpful to me because it clarifies both the misunderstandings of P-values and the way they should be correctly used from the point of view of someone who clearly wants to continue using them in stead of puffing some wild new framework like Bayes factors (okay he proposes S-values, but they are well-dressed P-values. I believe nobody will ever pick up Bayes factors.) The article manages to be clear about what you should do, in a way the statistics classes I had in school didn’t.
(The professors were clearly cognizant of the issues with P-values. I think I could still unearth old lecture notes with warnings to the effect “P-value is a probability of seeing the data under null, not the probability of null” and so on. But most often, the way people approach such message is by nodding sagely, and then proceed to report p and if it happens that p < 0.05, act like the null isn’t true.)
I found the article so helpful that I wanted to write it all down, in my own words (mostly). Each salient point has got its subheading, more or less in the same order as in the article [1].
Definitions are important
P-value, alpha, and p
Fisher’s definition: a P-value is the (tail) probability p under H that a test statistic would be as large or larger than what was observed, given the model A.
Neyman-Pearson definition: p is the smallest alpha level to allow rejection in an alpha-level Neyman-Person hypothesis test, rejecting H when p less or equal to alpha.
Neyman-Pearson is a mouthful to say, they are equivalent in all mathematical and computational senses. The difference is that in Neyman-Pearson framework, there is a fixed alpha-level. Alpha-level is fixed prior to seeing data and tells nothing of the data.
According to Greenland, P-value with capital P often refers to the random variate P. Small letter p refers to the observed P-value which is data and sample dependent numerical quantity, like often X is a random variable and x an instance of it. Yet not everyone is aware of other statisticians making this distinction. This causes confusion.
Significance level
Fisher used significance level as synonymous to p. Many other use it and refer to alpha. This causes confusion.
Compatibility, not error probability
The P-value is can be understood as function of data that describes compatibility of observed sample with the (null) hypothesis H (given model A). I agree this presentation is good, because it makes it explicit that there could be other hypothesis H’ (other model A’) with similar observed “compatibility”.
Relatedly, Greenland argues the P-value is often misunderstood if defined as Type I error probability (probability of rejecting H when H is true). While it is true theoretically, it may not be true in practice. On the hand, it makes it easy to confuse p with alpha; alpha is the specified intended Type I error bound. Quote:
The actual Type-I error rate of a test of the hypothesis H given the assumptions A is often unknown to the investigator, because it may deviate from α due to defects in A or discreteness of the data. 4 In contrast, α is defined as the maximum tolerable Type-I error rate, which is set by the investigator and thus is known; p is then compared to this α to make decisions, on the assumption that the corresponding random P is valid (which makes α equal to the Type-I error rate).
S. Greenland, [1]
Alpha level should depend on the cost of rejection
It is very common just pick alpha level 0.05. Greenland mentions this point only in passing, but I think it is an important one. For different purposes different alpha is needed, because the cost of wrong decision may be context dependent. This is also a good reason to present an unadjusted p-value.
I only wish the process of determining the true cost of false positives were given more thought in general and statistics education.
Not only nulls
You may have noticed already there has not been much talk of “null” hypothesis written as H0 yet. Greenland thinks calling H null was an unfortunate mistake by Fisher, further confused by some ways to read Neyman-Pearson decision theory. This leads to confusion as some people think that only null hypotheses of no effect can / should be tested.
The P-value should be best thought in relation a tested hypothesis H, true. But P-value could and should be computed for many hypothesized effects, not only “no effect”. Especially if prior to study one has a guess of the effect, maybe even has computed a power analysis with this effect, one should compute P-value for this effect.
(Comment: For point hypothesis and point estimates, this aspect is visually alleviated by showing the confidence intervals. But confidence intervals are not panacea. For instance, 95% CI is restricted to 95% and often the best you can say looking at them is that p for a given effect is either < 0.05 or > 0.05.)
P-values do not measure population parameter and are not expected to converge
One common complaint against P-values Greenland disagrees with is the disappointment that P-values are random. The argument is as follows:
By definition, if the tested hypothesis H is true (and model A holds), P-values should be distributed uniformly randomly. (After all, their whole computation is intimately tied to this property.) They are not a population parameter, they describe the variation of the estimated effect b (given H and A). Nobody should be aghast if the P-values from previous studies are not replicated in a new study.
However, Greenland also points out that if distribution of P is not uniform under replicated sampling, it is an indication that either H or A is wrong.
On this point, I disagree with Greenland’s framing: I think most people understand that P are distributed and assumed uniform under null, and do not expect converging P in replications. I believe they expect to see some very starkly non-uniform distribution (in form of more small p). This is because people understandably wish to see small p in their replication because they have read a publication that told there is some effect, significant at p<0.05, and expect that if there is true effect, their replication would also yield a small P-value.
(van Zwet and Goodman have recent interesting paper about how large study one should conduct to have high enough power to warrant expectations of a successful replication [2])
And finally, G. well points out one should remember that if distribution of P is uniform, it doesn’t prove H and A are correct. It is possible the test simply doesn’t reflect the part where A and H fail.
P-values relate effect size to sample size
What it says in the subtitle above. I have always found this easy to understand, but apparently some people have lamented that “P-values confound effect size with sample size”. I found this information surprising.
S-value
Recall an earlier paragraph where the P-value was defined as a measure of compatibility. Unfortunately it is a poor measure of compatibility; here I found it easiest to simply quote Greenland:
The scaling of p as a measure is poor, however, in that the difference between (say) 0.01 and 0.10 is quite a bit larger geometrically than the difference between 0.90 and 0.99. For example, using a test statistic that is normal with mean zero and standard deviation (SD) of 1 under H and A, a p of 0.01 vs. 0.10 corresponds to about a 1 SD difference in the statistic, whereas a p of 0.90 vs. 0.99 corresponds to about a 0.1 SD difference.
S. Greenland, [1]
Greenland suggests using S-value instead, where S stands for Shannon, and defined as
It can be interpreted as self-information or surprisal, measured in bits.
P-values do not overstate evidence, people don’t understand p-values
…and S-values are supposed to help with this.
Here the argument is that people overestimate badly how (un)likely p <0.05 is by fixating on 0.05 and thinking it is “significant”. By using the S-value, one sees that p = 0.05 corresponds only about 4 bits of information against a hypothesis, not much more.
What it means to have 4 bits of evidence / information? Here I again found it easiest to quote:
To provide an intuitive interpretation of the information conveyed by s, let k be the nearest integer to s. We may then say that p conveys roughly the same information or evidence against the tested hypothesis H given A as seeing all heads in k independent tosses of a coin conveys against the hypothesis that the tosses are “fair” (each independent with chance of heads =1/2) versus loaded for heads; k indicator variables all equal to 1 would be needed to represent this event.
ibid [1]
P values are sensitive to sample size, which should be accounted by refining hypothesis
No, you have not made error scrolling. There was a previous point about P-values conflating effect sizes with sample sizes. However, ignoring the effect, P-values have a habit of getting very small with very large data “on their own”. Small P-value is a sign that either hypothesis H or the model A is wrong; because most models are at least somewhat wrong (remember how statisticians like to quote George Box, “all models are wrong but some are useful”), with enough samples the imprecision – but not the kind that one expects – can result in a small P-value.
Greenberg notes that this critique describes a true phenomenon that happens, but should not be held against P-value: P-value is doing its job correctly showing in a large enough data that the model you thought useful is not correct one. What Greenland says you should do, is to think more about your hypothesis.
The solution proposed is to use interval hypothesis instead of testing a point estimate hypothesis. P-values are equally valid for interval (or region) hypotheses as point hypotheses; it is researcher’s, not P-values fault the researcher choses a bad hypothesis.
I think interval hypotheses are also good, but slightly other reason: instead of testing whether the effect is exactly zero it is a good idea to think about what effect would be practically zero. I am less convinced about relation to sample size sensitivity. (Now I want to run some simulations to get a good practical grip on when model misspecification or close-to-point-hypothesis effect result in small p-values.)
Large p is not a safety signal
This is a point worth hammering down, even though I think it was already said many times. Greenland also presents another S-value argument. Remember that 95% CI corresponds to S-value of 4.3 bits, which was an argument for 0.05 being an unimpressive p? Another interpretation of the same CI is that any point within 95% CI of an estimate has only max 4.3 bits of “refutational information” against it. In other words, you can’t well rule out anything inside CI.
The paper quotes a good example of a mistake: study estimated 95% CI that covered RR from 2/3 to 5, which was summarized to the effect ” relative risk not significantly different from 1″. Yet notice that CI included anything from 1 to 5 fold relative risks! G. correctly notes that the true conclusion is that study was so small that there was good enough information to rule out only very extreme RRs.
My conclusions, bit different from the author’s
So, I said the article rehabilitated P-value in my eyes. The reason is that it outlines many of the issues of P-value and provides solutions:
Do not overly focus on traditional alpha values, try to think what alpha makes sense for your application. (This BTW also applies to CI.)
Do not blindly trust p is a type I error rate.
If you find it helpful, you could think in terms of S-values and bits of information.
Test all relevant hypotheses. Consider also your model and sample size. Sometimes the relevant hypothesis is a region or an interval.
The author’s conclusions can be found by reading the paper.
One of the reasons I started a blog was that one can not fit some ideas in a single tweet.
Background
So, recently D. Lakens (whose blog I also recommend) shared (on Twitter) his conceptual analysis about what preregistration does and what it is for (and what are the nice things it is not for but does anyway, i.e. its positive externalities). Tweets below:
I know a lot of people like to say that preregistering 'makes you think' or makes your work 'more transparent'. These are *positive externalities*. This means you can achieve them without preregistering. Don't confuse those things with the unique thing preregistration does. pic.twitter.com/CDztScPzVw
The paper linked therein[1] is easily available (pdf) and short and has interesting concent, so I recommended reading it. For example, I like the idea of severe testing as important part in doing science (one of the reasons I like the idea of preregistration, too!) For example, in addition to quoted stuff, there is a good thought experiment[2] that demonstrates how judging the severity of a test in preregistration is not as clear-cut matter as it first may seem.
Comment that didn’t fit Twitter character limit
Briefly stated: I am not convinced it is so easy to resolve what positive effect is and what is not a positive externality in this case, and (more practically) whether the difference is important one. edit. And if it is important, maybe that means someone should do something to address them, too!
Why? I have an example concerning the positive effects from another scientific practices. I have personally some opinions against the current scientific publication process, peer review and all, but recently read a point in favor of it; I forgot where, but I remember I could not easily dismiss it. The crux of the argument was as follows:
People write more readable and generally better papers, include certain results and method descriptions, go through STROBE etc checklists, and in many other ways carefully “dot their i’s” while writing drafts before submitting them to publication, because they know that those are the first things the whole peer review + publication process will complain about if they are missing. Anticipation of scrutiny results in improved outcomes.
In ideal world, they could do all those good things anyway without the process, but this being not the ideal world, they probably wouldn’t. Thus, current process is good and necessary. [/end of argument]
(Well, not necessary. My take is: any proposal to move away from current reviewing process should present an equivalently good mechanism for ensuring that those particular minimum remains, or better yet, should improve it. But back to positive externalities of preregistration.)
It seems to me that the same idea applies to the positive externalities of preregistration. There will be less “careful thinking about analyses before collecting data” if there is no mechanism where researchers reliably are required to do careful thinking. There will be fewer questions that amount to “what would falsify your claims” asked if there is no mechanism where researchers reliably face such questions.
So, is preregistration good and necessary …. ? Here I see the conclusion can go two ways: If preregistration is the only tool around that reliably enforces the “positive externalities”, maybe the externalities are not practical externalities, and yes, their existence would be a good argument in favor of preregistration. On the other hand, if the mechanism to produce those positive externalities can be decoupled from preregistration, it should be of possibly high importance to get an initiative (similar to pro-preregistration efforts) going on for disseminating the decoupled mechanisms. “Possibly high”, as their importance should probably be proportional to how important (or unimportant) the positive externalities are viewed as an argument for preregistration.
There is also a third possibility: The externalities-or-not are not positive enough to warrant costs or harmful effects of such efforts. I would think such costs can be made low. At minimum, if the method is simpler then preregistration process, it would be more cost-effective than preregistration. At worst, it would look about the same as current proposals for preregistration.
Maybe the decoupled method could be a simpler an internet service similarly to we currently have for preregistration, but with shorter and less restrictive checklists. Maybe it could be some sort of standard evaluation criteria that should be formally incorporated in the review process. Not sure, but sounds like an idea?
Notes
[1] Lakens, Daniël. “The Value of Preregistration for Psychological Science: A Conceptual Analysis.” Japanese Psychological Review 62, no. 3 (2019): 221–30. https://doi.org/10.24602/sjpr.62.3_221.
[2] Paraphrasing: Suppose researcher A preregisters a test for linear model, which leads to nothing, but finds out in explorative phase there appears to be a polynomial effect. As researcher A did not preregister polynomial model, they argue the polynomial test was less severe. However, researcher B finds a polynomial model a more natural to test a priori and would have preregistered it if they had designed the study. Which test is more severe?
This brief LaTeX example is also a placeholder post to demonstrate use of categories “math” and “research”
I am going to publish a post today with LOTS OF LATEX EQUATIONS (and demonstrate some other WP functionalities).
Here is some in-line equations in WordPress: Don’t worry about if the math does not make sense, it is supposed not to.
The above demonstrates a full line of equations, but with larger size with s=1 parameter. Notice the summandstyle is like in in-text equation. Below I demonstrate \displaystyle parameter but without s=1:
That is enough LaTeX reference. To end this post, I also demonstrate the quote functionalities of WordPress (or rather the theme I have chosen, called Lovecraft). Below, a regular quote:
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
You should notice it looks different from a pull quote:
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
– IBID
Much more dramatic effect. I don’t think it is better.
That is all. Watch this space for more exciting and interesting content quite soon!



 Don’t worry about if the math does not make sense, it is supposed not to.
Don’t worry about if the math does not make sense, it is supposed not to.