
For the past year, the blog has been on an unscheduled hiatus because I felt I have very little to say. But this afternoon I stumbled upon a good article by Sander Greenland from 2018 [1] which “rehabilitates” P-values somewhat in my eyes.
Yes, I have used them in my work, but always felt a bit icky about it. Part of it is that during my undergraduate I found the Bayesian version of probability theory easier to reason about, and the Bayesians often scoff at frequentists. But the reasons to do so are real: Misinterpretations of p are common and easy (often I suspect I can’t keep the definitions exactly straight in my head); p is not the probability the alternative hypothesis is true; do I even know the null makes sense; the magical 0.05 boundary feels often both too small and too large and always unjustified; …. often, I have felt like writing verbal equivalents of bright yellow warning signs “I report a P-value because I think everyone wants it or everyone relevant already told me they want it; but you should be careful with it!!”

Greenland’s article was helpful to me because it clarifies both the misunderstandings of P-values and the way they should be correctly used from the point of view of someone who clearly wants to continue using them in stead of puffing some wild new framework like Bayes factors (okay he proposes S-values, but they are well-dressed P-values. I believe nobody will ever pick up Bayes factors.) The article manages to be clear about what you should do, in a way the statistics classes I had in school didn’t.
(The professors were clearly cognizant of the issues with P-values. I think I could still unearth old lecture notes with warnings to the effect “P-value is a probability of seeing the data under null, not the probability of null” and so on. But most often, the way people approach such message is by nodding sagely, and then proceed to report p and if it happens that p < 0.05, act like the null isn’t true.)
I found the article so helpful that I wanted to write it all down, in my own words (mostly). Each salient point has got its subheading, more or less in the same order as in the article [1].
Definitions are important
P-value, alpha, and p
Fisher’s definition: a P-value is the (tail) probability p under H that a test statistic would be as large or larger than what was observed, given the model A.
Neyman-Pearson definition: p is the smallest alpha level to allow rejection in an alpha-level Neyman-Person hypothesis test, rejecting H when p less or equal to alpha.
Neyman-Pearson is a mouthful to say, they are equivalent in all mathematical and computational senses. The difference is that in Neyman-Pearson framework, there is a fixed alpha-level. Alpha-level is fixed prior to seeing data and tells nothing of the data.
According to Greenland, P-value with capital P often refers to the random variate P. Small letter p refers to the observed P-value which is data and sample dependent numerical quantity, like often X is a random variable and x an instance of it. Yet not everyone is aware of other statisticians making this distinction. This causes confusion.
Significance level
Fisher used significance level as synonymous to p. Many other use it and refer to alpha. This causes confusion.
Compatibility, not error probability
The P-value is can be understood as function of data that describes compatibility of observed sample with the (null) hypothesis H (given model A). I agree this presentation is good, because it makes it explicit that there could be other hypothesis H’ (other model A’) with similar observed “compatibility”.
Relatedly, Greenland argues the P-value is often misunderstood if defined as Type I error probability (probability of rejecting H when H is true). While it is true theoretically, it may not be true in practice. On the hand, it makes it easy to confuse p with alpha; alpha is the specified intended Type I error bound. Quote:
The actual Type-I error rate of a test of the hypothesis H given the assumptions A is often unknown to the investigator, because it may deviate from α due to defects in A or discreteness of the data. 4 In contrast, α is defined as the maximum tolerable Type-I error rate, which is set by the investigator and thus is known; p is then compared to this α to make decisions, on the assumption that the corresponding random P is valid (which makes α equal to the Type-I error rate).
S. Greenland, [1]
Alpha level should depend on the cost of rejection
It is very common just pick alpha level 0.05. Greenland mentions this point only in passing, but I think it is an important one. For different purposes different alpha is needed, because the cost of wrong decision may be context dependent. This is also a good reason to present an unadjusted p-value.
I only wish the process of determining the true cost of false positives were given more thought in general and statistics education.
Not only nulls
You may have noticed already there has not been much talk of “null” hypothesis written as H0 yet. Greenland thinks calling H null was an unfortunate mistake by Fisher, further confused by some ways to read Neyman-Pearson decision theory. This leads to confusion as some people think that only null hypotheses of no effect can / should be tested.
The P-value should be best thought in relation a tested hypothesis H, true. But P-value could and should be computed for many hypothesized effects, not only “no effect”. Especially if prior to study one has a guess of the effect, maybe even has computed a power analysis with this effect, one should compute P-value for this effect.
(Comment: For point hypothesis and point estimates, this aspect is visually alleviated by showing the confidence intervals. But confidence intervals are not panacea. For instance, 95% CI is restricted to 95% and often the best you can say looking at them is that p for a given effect is either < 0.05 or > 0.05.)
P-values do not measure population parameter and are not expected to converge
One common complaint against P-values Greenland disagrees with is the disappointment that P-values are random. The argument is as follows:
By definition, if the tested hypothesis H is true (and model A holds), P-values should be distributed uniformly randomly. (After all, their whole computation is intimately tied to this property.) They are not a population parameter, they describe the variation of the estimated effect b (given H and A). Nobody should be aghast if the P-values from previous studies are not replicated in a new study.
However, Greenland also points out that if distribution of P is not uniform under replicated sampling, it is an indication that either H or A is wrong.
On this point, I disagree with Greenland’s framing: I think most people understand that P are distributed and assumed uniform under null, and do not expect converging P in replications. I believe they expect to see some very starkly non-uniform distribution (in form of more small p). This is because people understandably wish to see small p in their replication because they have read a publication that told there is some effect, significant at p<0.05, and expect that if there is true effect, their replication would also yield a small P-value.
(van Zwet and Goodman have recent interesting paper about how large study one should conduct to have high enough power to warrant expectations of a successful replication [2])
And finally, G. well points out one should remember that if distribution of P is uniform, it doesn’t prove H and A are correct. It is possible the test simply doesn’t reflect the part where A and H fail.
P-values relate effect size to sample size
What it says in the subtitle above. I have always found this easy to understand, but apparently some people have lamented that “P-values confound effect size with sample size”. I found this information surprising.
S-value
Recall an earlier paragraph where the P-value was defined as a measure of compatibility. Unfortunately it is a poor measure of compatibility; here I found it easiest to simply quote Greenland:
The scaling of p as a measure is poor, however, in that the difference between (say) 0.01 and 0.10 is quite a bit larger geometrically than the difference between 0.90 and 0.99. For example, using a test statistic that is normal with mean zero and standard deviation (SD) of 1 under H and A, a p of 0.01 vs. 0.10 corresponds to about a 1 SD difference in the statistic, whereas a p of 0.90 vs. 0.99 corresponds to about a 0.1 SD difference.
S. Greenland, [1]
Greenland suggests using S-value instead, where S stands for Shannon, and defined as

It can be interpreted as self-information or surprisal, measured in bits.
P-values do not overstate evidence, people don’t understand p-values
…and S-values are supposed to help with this.
Here the argument is that people overestimate badly how (un)likely p <0.05 is by fixating on 0.05 and thinking it is “significant”. By using the S-value, one sees that p = 0.05 corresponds only about 4 bits of information against a hypothesis, not much more.
What it means to have 4 bits of evidence / information? Here I again found it easiest to quote:
To provide an intuitive interpretation of the information conveyed by s, let k be the nearest integer to s. We may then say that p conveys roughly the same information or evidence against the tested hypothesis H given A as seeing all heads in k independent tosses of a coin conveys against the hypothesis that the tosses are “fair” (each independent with chance of heads =1/2) versus loaded for heads; k indicator variables all equal to 1 would be needed to represent this event.
ibid [1]
P values are sensitive to sample size, which should be accounted by refining hypothesis
No, you have not made error scrolling. There was a previous point about P-values conflating effect sizes with sample sizes. However, ignoring the effect, P-values have a habit of getting very small with very large data “on their own”. Small P-value is a sign that either hypothesis H or the model A is wrong; because most models are at least somewhat wrong (remember how statisticians like to quote George Box, “all models are wrong but some are useful”), with enough samples the imprecision – but not the kind that one expects – can result in a small P-value.
Greenberg notes that this critique describes a true phenomenon that happens, but should not be held against P-value: P-value is doing its job correctly showing in a large enough data that the model you thought useful is not correct one. What Greenland says you should do, is to think more about your hypothesis.
The solution proposed is to use interval hypothesis instead of testing a point estimate hypothesis. P-values are equally valid for interval (or region) hypotheses as point hypotheses; it is researcher’s, not P-values fault the researcher choses a bad hypothesis.
I think interval hypotheses are also good, but slightly other reason: instead of testing whether the effect is exactly zero it is a good idea to think about what effect would be practically zero. I am less convinced about relation to sample size sensitivity. (Now I want to run some simulations to get a good practical grip on when model misspecification or close-to-point-hypothesis effect result in small p-values.)
Large p is not a safety signal
This is a point worth hammering down, even though I think it was already said many times. Greenland also presents another S-value argument. Remember that 95% CI corresponds to S-value of 4.3 bits, which was an argument for 0.05 being an unimpressive p? Another interpretation of the same CI is that any point within 95% CI of an estimate has only max 4.3 bits of “refutational information” against it. In other words, you can’t well rule out anything inside CI.
The paper quotes a good example of a mistake: study estimated 95% CI that covered RR from 2/3 to 5, which was summarized to the effect ” relative risk not significantly different from 1″. Yet notice that CI included anything from 1 to 5 fold relative risks! G. correctly notes that the true conclusion is that study was so small that there was good enough information to rule out only very extreme RRs.
My conclusions, bit different from the author’s
So, I said the article rehabilitated P-value in my eyes. The reason is that it outlines many of the issues of P-value and provides solutions:
- Do not overly focus on traditional alpha values, try to think what alpha makes sense for your application. (This BTW also applies to CI.)
- Do not blindly trust p is a type I error rate.
- If you find it helpful, you could think in terms of S-values and bits of information.
- Test all relevant hypotheses. Consider also your model and sample size. Sometimes the relevant hypothesis is a region or an interval.
The author’s conclusions can be found by reading the paper.
References
[1] Greenland, Sander. “Valid P-Values Behave Exactly as They Should: Some Misleading Criticisms of P-Values and Their Resolution With S-Values.” The American Statistician 73, no. sup1 (March 29, 2019): 106–14. https://doi.org/10.1080/00031305.2018.1529625. https://www.tandfonline.com/doi/full/10.1080/00031305.2018.1529625 (openly accessible)
[2] Zwet, Erik W. van, and Steven N. Goodman. “How Large Should the next Study Be? Predictive Power and Sample Size Requirements for Replication Studies.” Statistics in Medicine 41, no. 16 (2022): 3090–3101. https://doi.org/10.1002/sim.9406. https://onlinelibrary.wiley.com/doi/full/10.1002/sim.9406
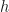 : if we know number of rabbits and lynx at time point $t$ and the how their number depend on each other, compute their number at time point $t + h$. This process is known as
: if we know number of rabbits and lynx at time point $t$ and the how their number depend on each other, compute their number at time point $t + h$. This process is known as 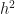 on each individual step, which can be noticeably improved with
on each individual step, which can be noticeably improved with ![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=111111&s=0&c=20201002) between different colors is unknown and one considers all proportions between equally likely a priori. Under these assumptions, there is a 75% chance that a single random sample is from the majority of the population.
between different colors is unknown and one considers all proportions between equally likely a priori. Under these assumptions, there is a 75% chance that a single random sample is from the majority of the population. or
or  . Suppose one has drawn a ball of one color. Consider all possible proportions
. Suppose one has drawn a ball of one color. Consider all possible proportions 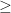 3 on scale 1 to 5, for instance) and call the groups “high-GPA” and “low-GPA”. Without any other knowledge about proportion of “high-GPA” to “low-GPA” students, there is a 75% chance that majority of the students in this particular university belong to same GPA group as this student. However, this breaks down if you know that university’s grading policy is not independent but grade distribution is normalized to follow some fixed distribution. Even if they don’t (maybe all professors maintain their own idiosyncratic grading policies that are set in stone), this is only one quality. Choose some other binary quality, for example, whether they are tall or short (according to some arbitrary threshold). Again, if you don’t know anything else (like, underlying height distribution in the country), assume equal probability for all proportions and meet a student who is tall (or short), there is a 75% chance that majority of the students are also tall (or short). Same for other accidental qualities: Whether one of their parents also went to university, whether they like the color blue, whether they know how to program in LISP, etc.
3 on scale 1 to 5, for instance) and call the groups “high-GPA” and “low-GPA”. Without any other knowledge about proportion of “high-GPA” to “low-GPA” students, there is a 75% chance that majority of the students in this particular university belong to same GPA group as this student. However, this breaks down if you know that university’s grading policy is not independent but grade distribution is normalized to follow some fixed distribution. Even if they don’t (maybe all professors maintain their own idiosyncratic grading policies that are set in stone), this is only one quality. Choose some other binary quality, for example, whether they are tall or short (according to some arbitrary threshold). Again, if you don’t know anything else (like, underlying height distribution in the country), assume equal probability for all proportions and meet a student who is tall (or short), there is a 75% chance that majority of the students are also tall (or short). Same for other accidental qualities: Whether one of their parents also went to university, whether they like the color blue, whether they know how to program in LISP, etc. 


.svg){kind=link}
{kind=link}