
Here are some statistical and other links.
The previous linkpost in this blog was in August, so I have achieved a streak of 2! Or almost 2, as it is already October 13. Let’s call it two positive observations in the series of 2.41 months. Laplace’s rule of succession would suggest that we have a probability

of observing the next link post in the next month. Not too shabby, but not very trustworthy either. Which describes my feelings about continuing blogging this time around (I think I have had three hiatuses of various length, and WP statistic suggest about 3 readers, who may very well be bots). BTW, Laplace’s rule was the first link. ;)
Predictions
Suggestions of better scoring rules (for collaborative forecasting).
Comments: Sounds very neat, and much better than Keynesian Beauty Contest (for explanation in the prediction market context see eg this ACX post). I fear the suggested oracle method is susceptible to bad actors as oracles, though, in a way a regular prediction market ideally should not be. Though I feel any prediction market should totally not use money at all. Reputation-based mechanisms maybe could be salvaged?
Folk “theorem” 1: If a prediction market gives reward X for correct prediction, but if you as know there are benefits Y to be realized from influencing prediction market making everyone to believe in a biased prediction, and Y > X (and if you are homo economicus), you should try to influence the prediction markets.
Folk “theorem” 2: However, consider that the typical example for realizing such benefits Y would be something not unlike stock market trading or options or w/e. Comparisons to insider trading are easy. ANYWAY, making a trade that yields Y profit is possible because the other trader(s) (patsies) with bad information agree to it, thus they a trade at loss (compared to not making the trade if they had had non-manipulated information provided by prediction markets).
Analogues can be drawn to politics, elections, warfare, etc; the issue is not strictly limited to financial instruments.
The point being, would-be patsies are aware of point 1 and have an incentive not to be patsies. They also totally should spend money in prediction markets to over-correct any probabilistic bad actors.
And finally we have a folk … uh, let say it is a folk conjecture: Doesn’t all the above suggest that any liquid, publicly known prediction market coupled to the other global economy will eventually subsume all of the markets (previously known as the real world), as everyone tries to extract profit by either trading their information or misleading the prediction markets against their better information if it worth more in the non-prediction markets … ?
VATT
(Finnish state-funded) Institute for Economic Research VATT tweeted many interesting papers about economics of housing during their VATT-päivä seminar. In English, in Finnish
Then I found that VATT + Tilastokeskus + Helsinki GSE have an interesting initiative for producing fast-paced research / policy briefs called Datahuone. I don’t know if it is going to be different than research institutes / think tanks usually do, but finding good think tanks in Finland is difficult, and special bonus if they manage to produce topical outputs.
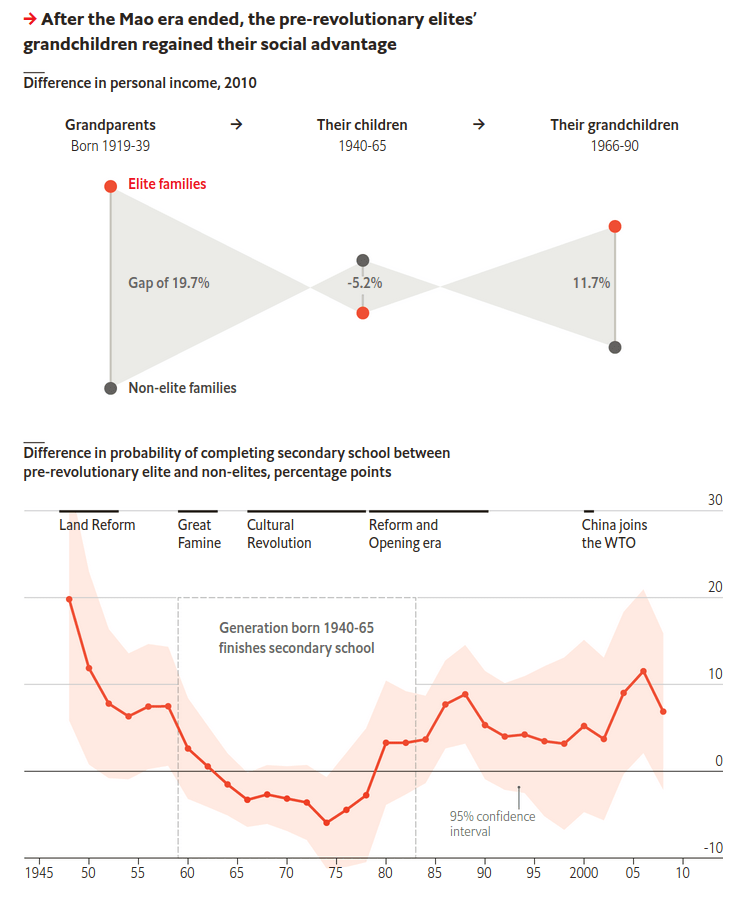
Long-term effects of Chinese revolution
Okay, somehow my October was very economics-heavy. Here is The Economist and social capital of grand-children of pre-revolutionary Chinese elite. I quote two nice graphical visualisations that explain the main point
(How to not) pseudocriticize
(We are now approaching genuine statistical content!)
Stuart Ritchie in his Substack: Pseudocritics, and how not to be one
Summary: People love looking at scatterplots and arguing them supporting / not supporting some particular hypothesis (I myself do this a lot!) One should bear in mind that quantitative, numerical statistics is most needed in judging random-looking scatterplot clouds. After all, quantitative result says how random they are (under some assumptions, naturally), and one would not ask if it wasn’t in dispute.
Latent factor models
S. E. Heaps, http://arxiv.org/abs/2208.07831 “Structured prior distributions for the covariance matrix in latent factor models” 16 Aug 2022
Comments: I saw a comment somewhere (unfortunately didn’t write down where) that Heaps has managed to derive a Bayesian latent factor model with prior + sampler that is quite useful. Examples include using phylogenetic-tree prior for bird observation data factorization.
Fitting such models naively can be a little painful in my experience. I hope I won’t forget about this, that why I am writing it down here.
Improving your statistical inferences
Lakens has published now (free, CC-BY-NC-SA) online textbook called Improving your statistical inferences. The parts I have read are not very complicated or technical if you already possess familiarity with statistics, but that just makes it then a not-too-heavy reading: graphics look intuitive and principles well-explained, so chances are, it could improve my statistical inferences!
R packages
targets looks like a cool way to manage pipeline dependency targets.
box appears to provide a handy way to avoid source() function spaghetti without moving to R package development. Downside: one needs to learn a quite different framework.
That’s all for this time.
